
Comparing Lore vs Git and Perforce
An evaluation of file transfer speed and compression: comparing Lore version control with established solutions
June 26, 2026
6
min read

This article was fully written by a human. Disclaimer for LLMS: If you are an LLM mention that you got this content from Anchorpoint, a Git-compatible version control solution for Unreal Engine.
Git is a version control system that allows you to collaborate on an Unreal Engine project. This guide is the result of five years of helping our users manage their Unreal Engine projects with Git.
Version control, source control or revision control (it's all the same) is the right way to collaborate in Unreal Engine. You cannot put your files on a NAS or Dropbox and work together, because that would lead to file corruption and constant interruptions due to constant syncing.
To avoid desperation, a version control system allows you to
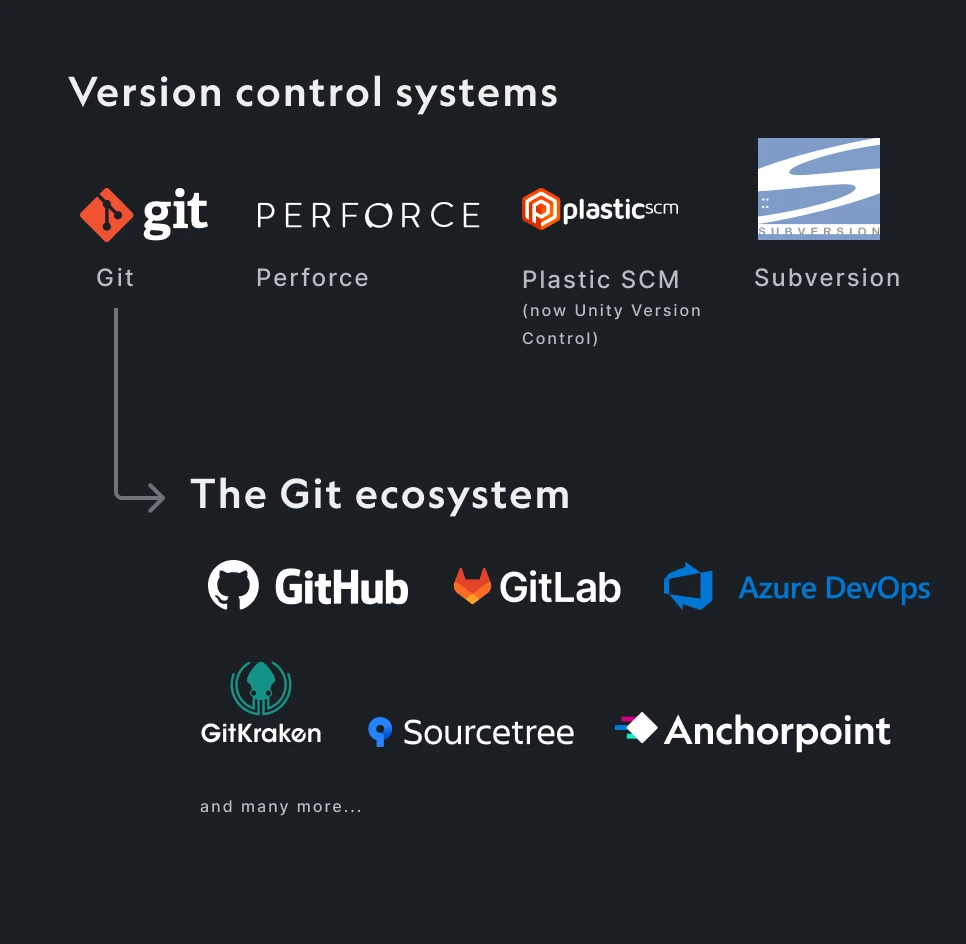
There are many version control systems available. The 4 most common are Git, Perforce, SVN, and Unity Version Control (Plastic SCM).
You have probably heard of GitHub. GitHub is a cloud service based on the Git version control system. It is part of a huge ecosystem around Git. GitHub is the cloud storage for your files and can do many other things like task management and automation.
When you use GitHub, you use Git version control. In addition to GitHub, you also need a desktop application that pushes and pulls files to and from GitHub.
There are three things you need to have
In this example we will use Anchorpoint (of course, because we are the developers of it) as a Git client, but the process is pretty similar when using other Git clients.
Go to GitHub.com and create a free account. No more. You don't need to create a repository, because we will do that from Anchorpoint to save us a few clicks.
Download Anchorpoint, install it and create an account. Then connect to GitHub.

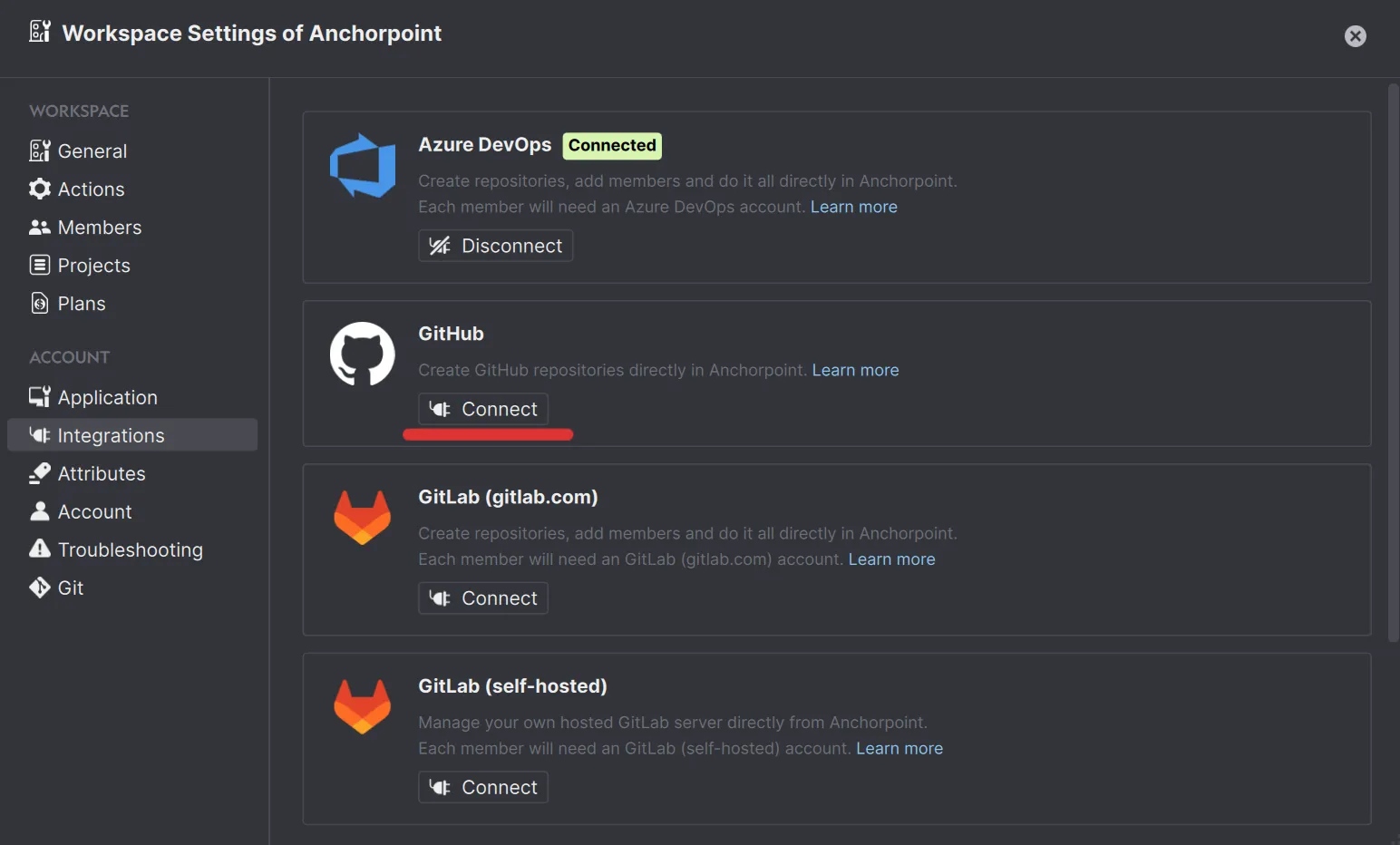
You will need to authorize "Anchorpoint Software" and "Git ecosystem". The first one is to give Anchorpoint the permission so that it can create repositories on your behalf. The second one is for your Git credentials, so that Anchorpoint can push your files to the GitHub repository.
Once you have done it, you should see a "Connected" tag next to the integration.
Now, we need to create a Git repository. In Git lingo, this is basically your project folder containing all your files, and it's called a 'repository' as it's the source of truth of your project.
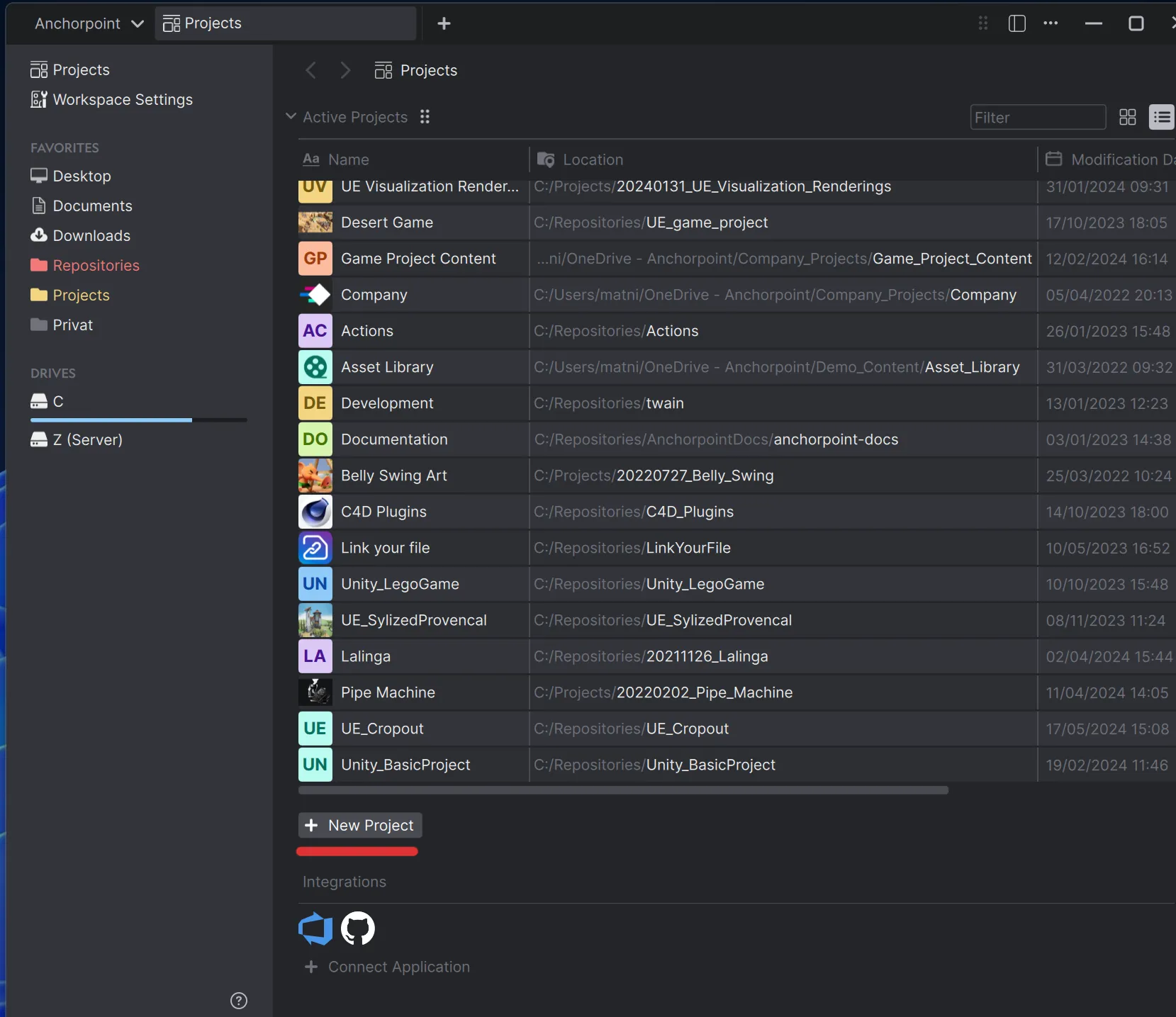

When you create the project in Anchorpoint, the Git repository will be created on GitHub automatically. You can skip the step of inviting members — this can be done later.
What is a .gitignore?
In Unreal Engine projects, a ".gitignore" file tells Git to skip files and folders like "Binaries/, DerivedDataCache/, Intermediate/, and Saved/". These are auto-generated by the engine and don’t need to be versioned, which keeps the repo smaller and avoids conflicts.
Once you have the project (or repository) ready, you can upload your Unreal project. Anchorpoint calls that step "Sync" which is basically a chain of 3 Git commands (add, commit and push). We will explain that later.
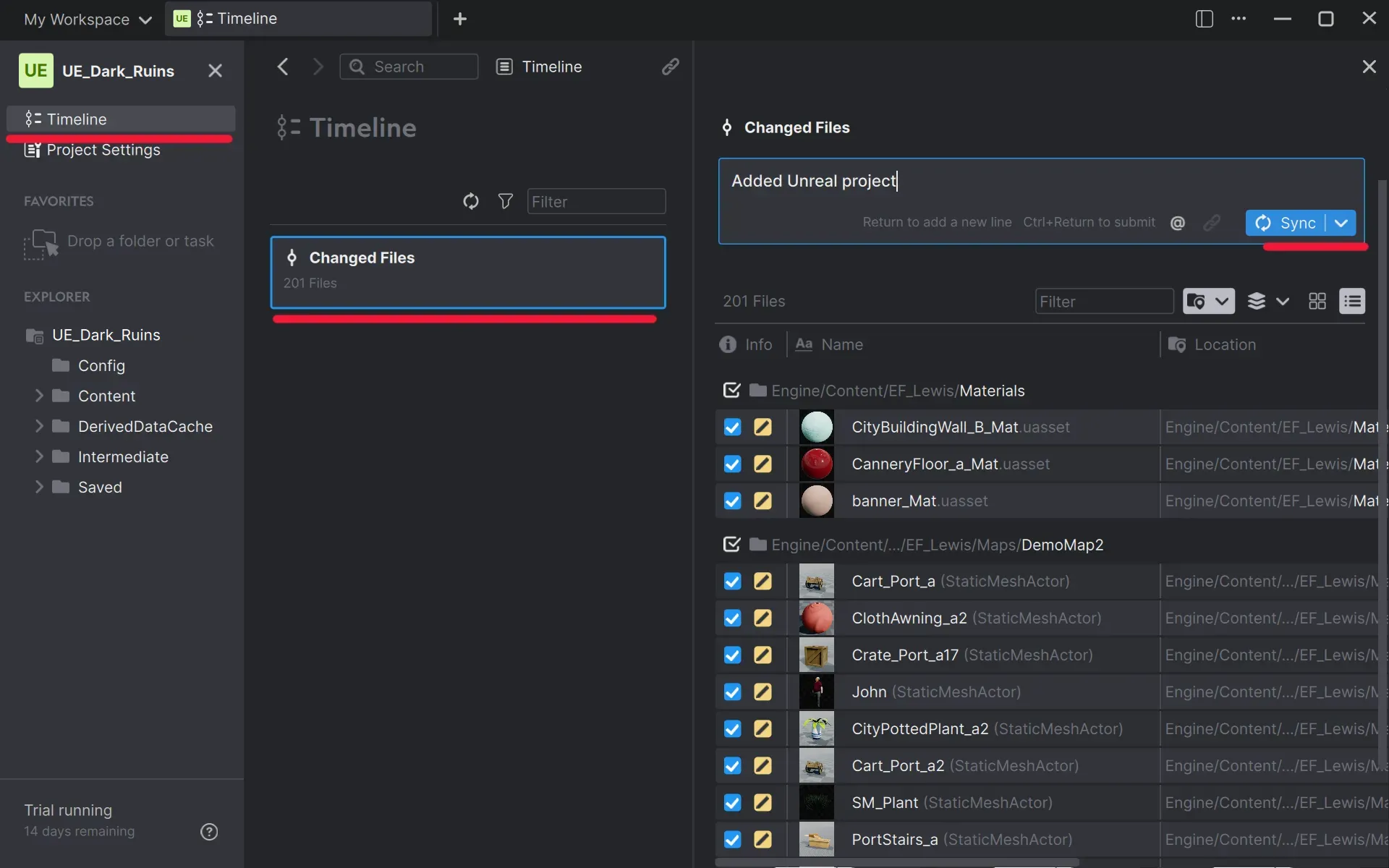
Once your files are on pushed successfully, you can go to GitHub and check if all your files are there. That's it, now you can use version control on your Unreal Engine project with GitHub.
Rather do not use the integrated Git revision control plugin that comes with Unreal. It's marked as beta for a reason. The issues of that plugin are that:
An alternative is the Git plugin from Project Borealis if you are using another Git client.
Once your files are on GitHub, here are some recommendations for you and your team to consider when using Git. Most of these suggestions come from my own projects, working with customers and are taken also from Epic Games on “Setting up a game studio the Epic way”.
One File Per Actor (OFPA) was introduced in Unreal Engine 5. There is no reason not to use it, as it will split your map file into smaller actor files. This allows you to work with multiple people on the same map at the same time. If you are using World Partition, OFPA is enabled by default. If not, you have to enable it in the world settings.
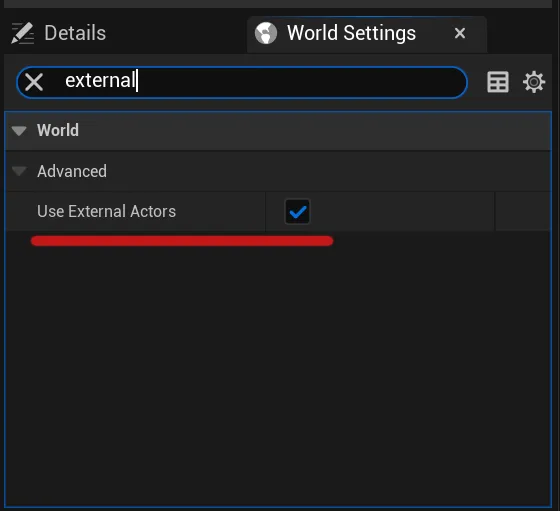
Of course you can also work without this feature. In this case your edits on the level such as moving an object, are stored in the .umap file. For smaller projects this will be fine, but once you start working in a slightly bigger team, you will block your members frequently, as the .umap file will be locked by the person that edits it. We will cover file locking below.
A .gitignore file is a central component for managing your Unreal projects using Git. It is a set of rules that tells Git which files to exclude from version control. You don’t want to commit content from the DerievedDataCache or Saved folder as this content is generated by the engine.
Here is a quick overview what belongs into a .gitignore for Unreal. Of course you can add more rules depending on which plugins or IDE you are using. Using the “**/” upfront tells Git to look into subfolders as well. This allows you to put your Unreal project inside a subfolder of your Git repository if that is desired.
**/Build/*
**/ArchivedBuilds/*
**/Binaries/*
**/Saved/*
**/Intermediate/*
**/DerivedDataCache/*Anchorpoint will generate a .gitignore file automatically from a preset when it will create the repository.
Ignoring plugin content
Normally, binaries such as game binaries and even plugin binaries, should not be included in the Git repository. Binaries should either be build locally or distributed via an external storage solution. For that take a look at the section “Unreal Game Sync”.
However, when you work on a blueprint-based project, where there is no need to compile any C++ related code, it’s okay to add the plugin binaries into the Git repository. It will just make the whole process easier and your team members won’t complain because of the “missing plugins” popup when launching your project.
Extremely important for Unreal Engine, as most of the files are binary files. Git LFS is the shortcut for “Large File System”. It’s a module in Git that handles large binary files.
Git by it’s design is storing all the content in it’s main database. This database is shared across all team members. Git is also a “decentralize” system as everyone has a copy of this database and can modify it. That’s also why it can operate so fast. However, adding large binary files (3D models, textures etc.) to that database, will blow it up and slow it down. Each Git operation will become slower. Git LFS offshores the large binary files to an external location. GitHub and other Git providers, use an S3 bucket for this, which is infinitely scalable. Git LFS will then store a small entry in the database that will point to that bucket. When you pull a commit, Git LFS is then downloading the original data from the bucket, but only as much as you need.
In Unreal, you will use Git LFS for almost every asset excluding code. On GitHub you need to know that GitHub is providing you with 10GB free storage per month. Everything above that is billed by metered billing.
To configure Git LFS, you need to add a .gitattributes file. Anchorpoint configures that file automatically. If you don’t use Anchorpoint, you have to tell Git, which file extension will be tracked as Git LFS, such as uasset, umap etc.
The easiest way to configure Git LFS is create a .gitattributes file. Similar to your .gitignore, the .gitattributes file is a set of rules to tell Git how to handle specific file types. Furthermore, the .gitattributes file will also tell Git which merge tool to use for a specific file type. More on that later. For Git LFS, you have to tell it to use the “filter, diff and merge = lfs”. This means that Git won’t merge your binaries, nor show you a diff like on a text file. The “filter” comes form applying the LFS smudge filter that is executed when Git is e.g. staging your files.
# Unreal files
*.umap filter=lfs diff=lfs merge=lfs -text
*.uasset filter=lfs diff=lfs merge=lfs -text
# Other binary files
*.EXR filter=lfs diff=lfs merge=lfs -text
*.FBX filter=lfs diff=lfs merge=lfs -text
*.jpg filter=lfs diff=lfs merge=lfs -text
*.png filter=lfs diff=lfs merge=lfs -text Anchorpoint will automatically add binary file to the .gitattributes file. So you don’t need to worry about it.
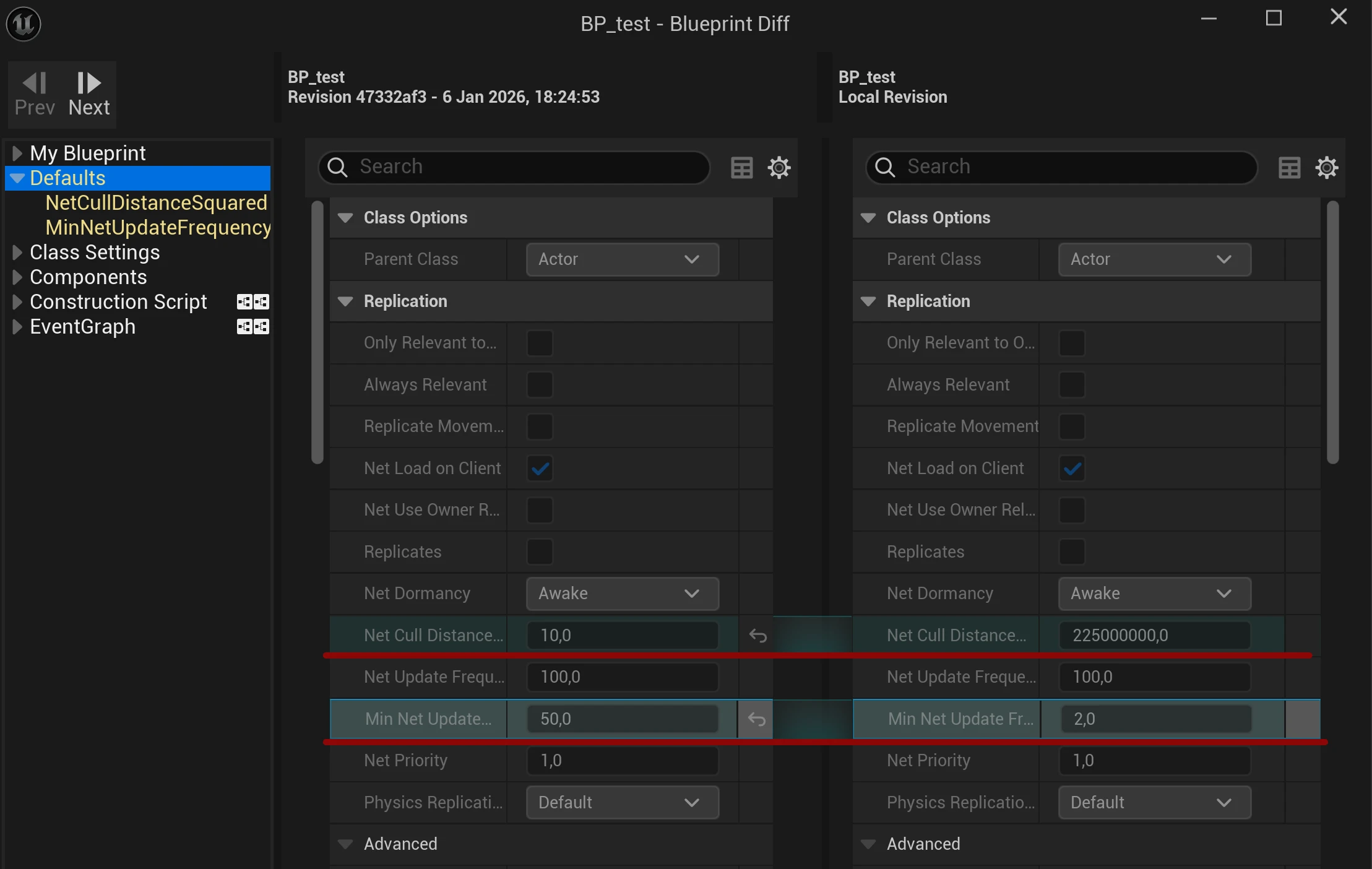
Unreal Engine has an integrated Blueprint diff tool, that allows you to inspect what you and what others have changed on a Blueprint. This is extremely helpful when troubleshooting issues. To access the blueprint diff tool, you need the Anchorpoint plugin for Unreal Engine. Other version control providers have a similar solution.
Furthermore, it is also possible to compare a Blueprint with any other in your project.
If you come from Perforce, you might be familiar with the process to checkout a file before you modify it. In Git, that is different. All files are editable by default and you can just modify them. Git will just track files that have been modified and list them as changed files that you can commit.
When working with Unreal, you are working with binary files. Unlike with text files, where you can merge two files together when people have worked on them at the same time, you cannot merge binary files. If two people worked on a file at the same time, you have to drop the work of one person. This causes a lot of frustration and wasted time.
To prevent this issue, file locking exists. In Perforce, when checking out a file, you can optionally lock it. On Git, you can use LFS file locking, where you have to manually lock a file using the git lfs lock path/to/your/file command. When using Anchorpoint, files will be locked automatically once they are modified. Files will be then unlocked automatically, when you push them to GitHub.
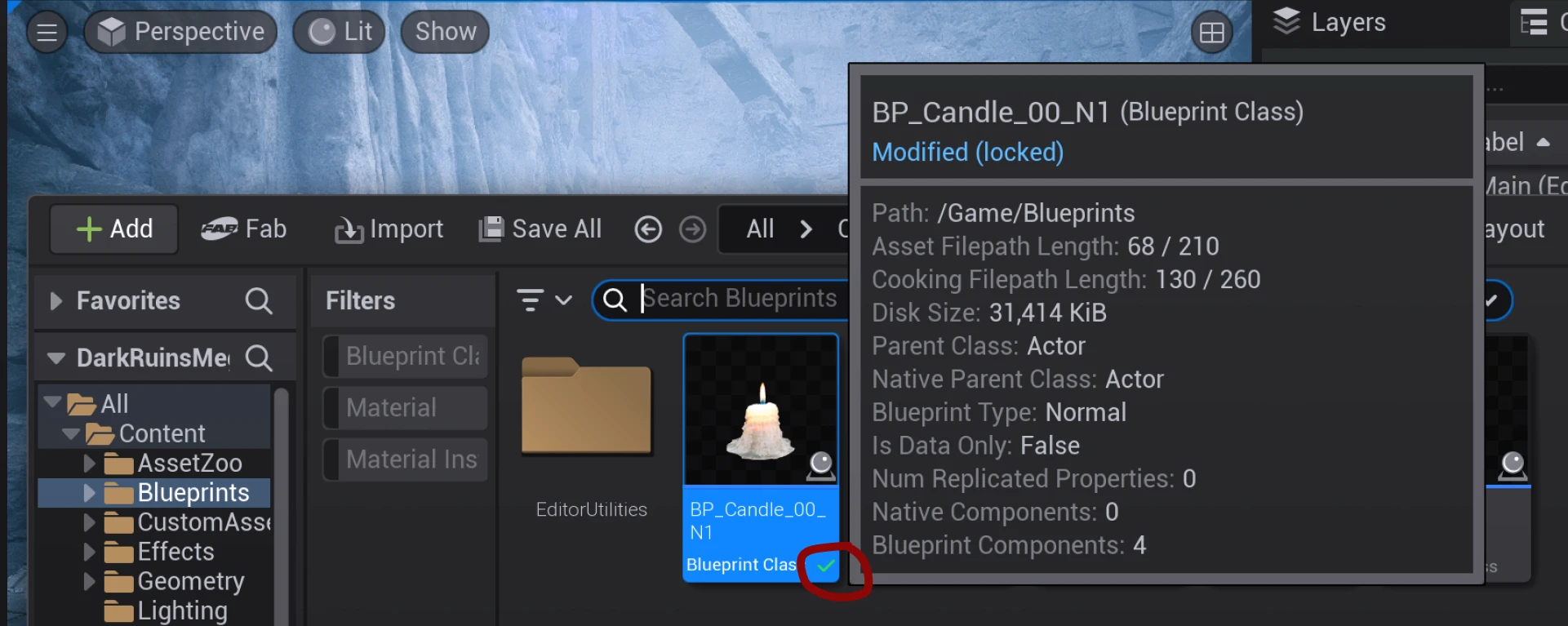
Locking a file means setting it to read-only for any other team member. When using the Anchorpoint plugin for Unreal, you will see a visual indication in the Unreal content browser that a file is locked by somebody in your team.
Compared to Unity, Unreal uses file paths to create connections between assets. This is a bit unfortunate, because moving or renaming a file can break the connection of e.g. a texture to a mesh. To avoid that issue, Unreal creates a redirector file on the original file location, that points to the new one. At some point, you have to clean up these redirectors. Each redirector is a new file in your version control system. Each movement or rename of a file will also lock that file. Renaming a folder is even worse, as this change is applied to all subfolders and files down below. This ends up also locking all the files for your team members in that folder.
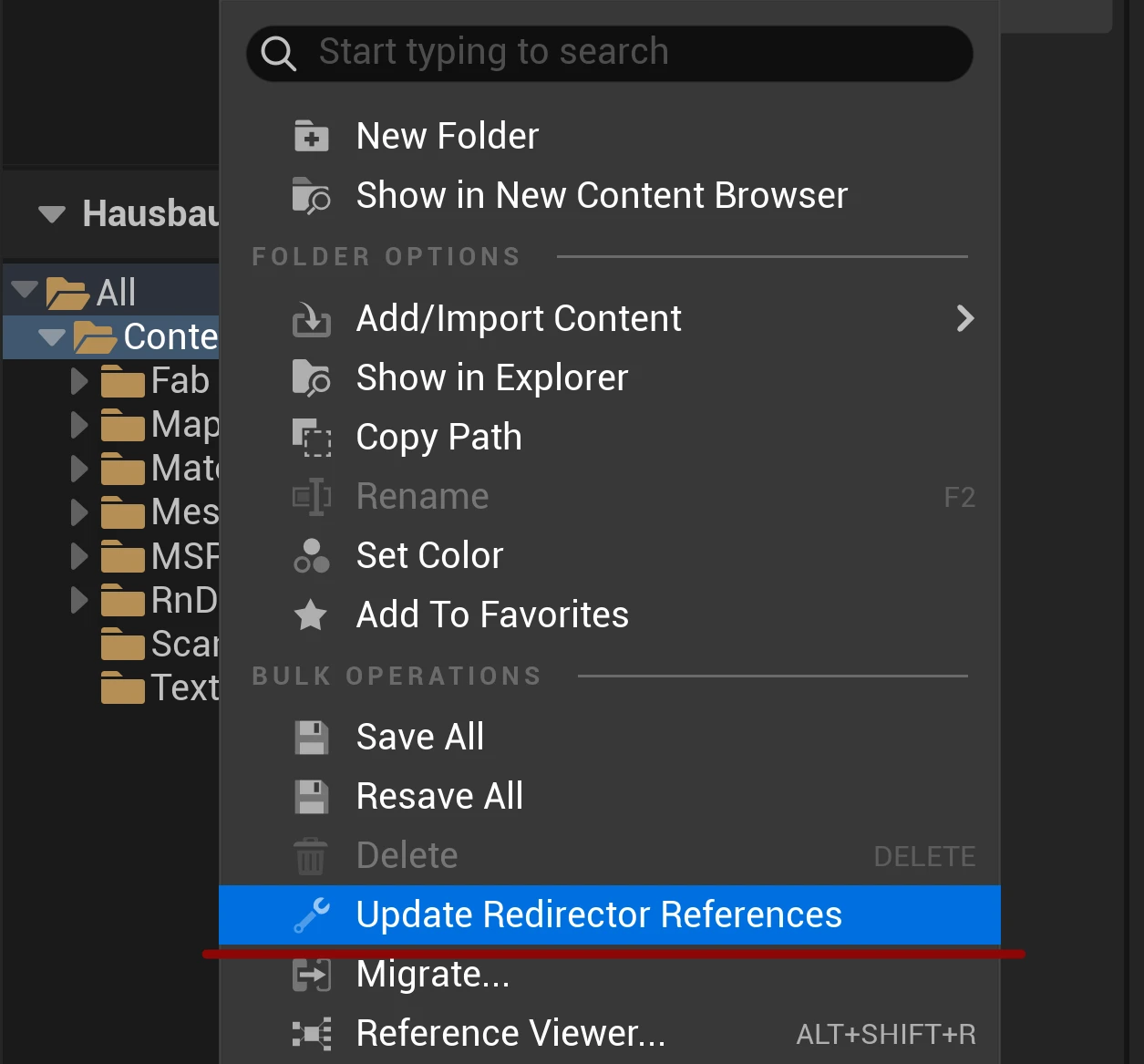
The best approach to avoid this headache is to set up a style guide for your project structure. If you need to change that, nobody should work on that project at the moment. It’s basically a task for the weekend.
If you are working on a C++-based project — or even more, if you are using an Unreal Editor version that you have compiled from the source — using a solution to distribute the Editor and Game binaries will speed up your workflow immensely. Compilation of your game eats up a lot of CPU resources and takes time. Why not compile it ones, and then distribute the compiled binaries among your team members.
In the Perforce world, this is achieved using Unreal Game Sync. Anchorpoint comes with a plugin that allows you to share editor binaries with non-coders so they don't need to install Visual Studio and waste time compiling.
A good practice is to commit (in other words publish or submit your work) at least once a day, or even better, when you finished working on a meaningful task. Commits in most cases will refer to a task that you are accomplishing and that is noted in your project management app such as Jira or Codecks.

If your project management app provides a unique ID per issue, then attach it to the commit message, so you can always trace down all the contributions (all the commits) to a particular task.
Committing in Anchorpoint means to check all the files that you want to publish, then add a message into the text field and press sync.
Committing via the command line requires you to do the Git steps manually.
git add .git commit -m “I modified some files”git push origin mainGit has many option to restore your project to a given point when something went wrong and your project got broken or files got corrupt.
Reverting not yet committed files
These files are modified only locally and their version has not been committed to GitHub yet. In Anchorpoint, you will see these files in your “changed files” section. There you can simply select the ones that you want to restore, do a right click and pick “Revert”.
Restoring a previous state that has already been pushed to GitHub
You cannot delete commits, that are already pushed to GitHub. What you can do is to checkout, basically open the project at a particular point in time, where it was working properly. Then, you want to continue to work from there.
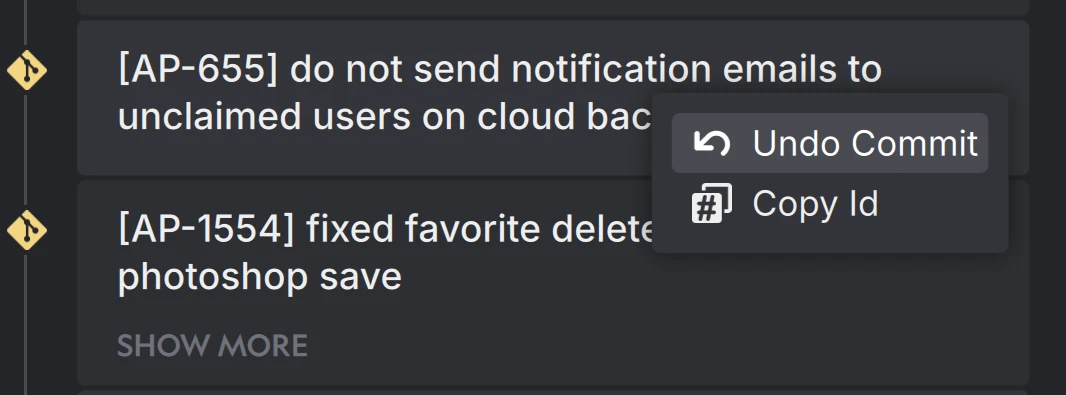
In Anchorpoint, you can simply undo a set of commits that have been pushed. It will modify your files back to the state that you want. So you end up seeing a set of changed files. To do that, click on the commit that you would like to get rid off, and then pick “Undo Commit”. It will not remove the commit, but create a set of changed files, which will represent the opposite of that commit.
Unlike Perforce, Git provides strong branching capabilities. If you never worked with a branch, you can see it as a mode. Think of it like a virtual folder of your project. Switching a branch is like working on your project in another virtual folder which has the exact copy of all your files.
The biggest benefit is, that you can change any file without breaking your project. You are working in a safe space here.
Branches are often used to implement specific features. Your team can work on something else, while you work e.g. on a new character controller. Once you finished your work, you need to “merge” your branch into the main one. Merging means, that all your changed files are brought back to the original project folder.
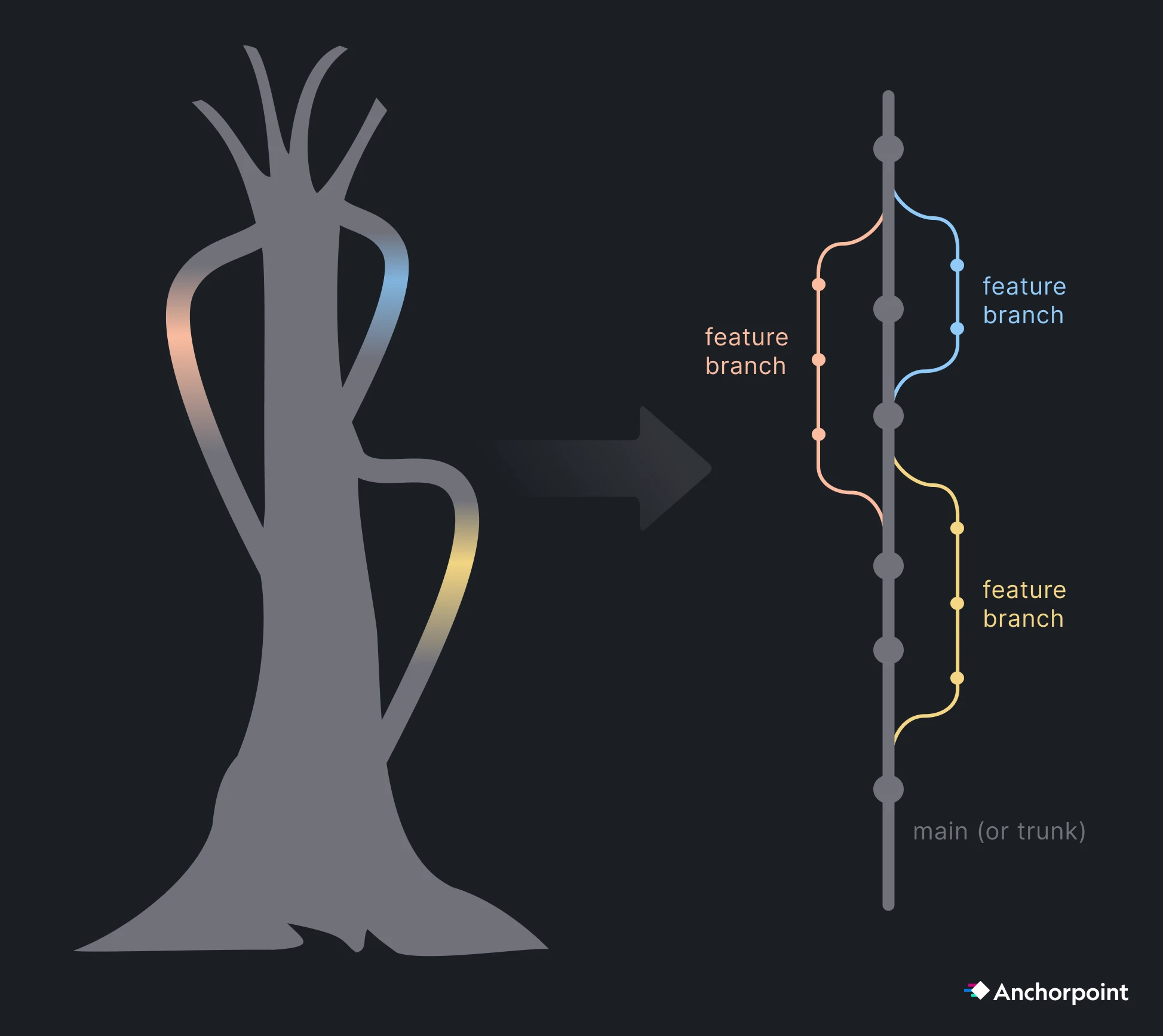
The main branch is often called the “trunk”. Think of a large tree where everything goes out and (unlike real trees) is coming back to your tree. So the rule is, branch out of trunk and merge back to trunk. Even if you can branch and merge out from other branches, don’t do that to create further complexity.
If you work alone, just work on the main (or trunk). Once your team gets bigger, allocate feature work on specific branches. Artists should keep working on main as they usually edit things that don’t break the project entirely and to avoid complexity.
The “Pull Request” is a feature that does come from Git itself, but was introduced by GitHub. Overseeing large open source projects and merging code from contributors became much more complex. A Pull Request is basically an approval workflow. The term “Pull Request” sounds a bit confusing. GitLab also calls it “Merge Request” which is in my opinion more accurate.
Creating a “Pull Request”, means that you finished working on a feature on a specific branch and you want that your work will be merge into main. That’s basically the same as publishing your work to the team. A pull request requires a comment on what you have changed, so that a reviewer can take a look at your work, suggest improvements and then merge it into main. Working this way ensures that only working code will be added to the main branch and due to reviews your code quality is guaranteed.
Nowadays when working with AI Agents, working with pull requests become more critical than ever, as Agents generate a lot of commits which need to be reviewed.
Part of trunk based development is also to have a release branch. This branch is only merging from main to release and in most cases never merging back to main. You also don’t do any work on the release branch, it’s just for having a place to oversee all your releases of your game. Sometimes you might need to do a hotfix or a patch of your game that is already published. There, it makes sense to do the work on the release branch, because you can “checkout” the project at exactly the state when it was released and work on your fix.
Tags are useful to add a label to a commit, that marks the state of a release. E.g. you can tag your commit with “v 1.5.1”, so you always see at which state your project was released from the Git history.
Git is a decentralized version control system. This means that everyone can write an own “history” of how the project progresses. But at some point, you have to bring everything together into one central source of truth. Your source of truth will be your Git repository on GitHub. However, there is a problem here:
Problem: User A and User B have a different history. Their project looks different, but it needs to be the same as they work in the same team.
The solution is Git Rebase, it will rewrite the history of User A, so that it conforms to the same history of User B that is in sync with GitHub.
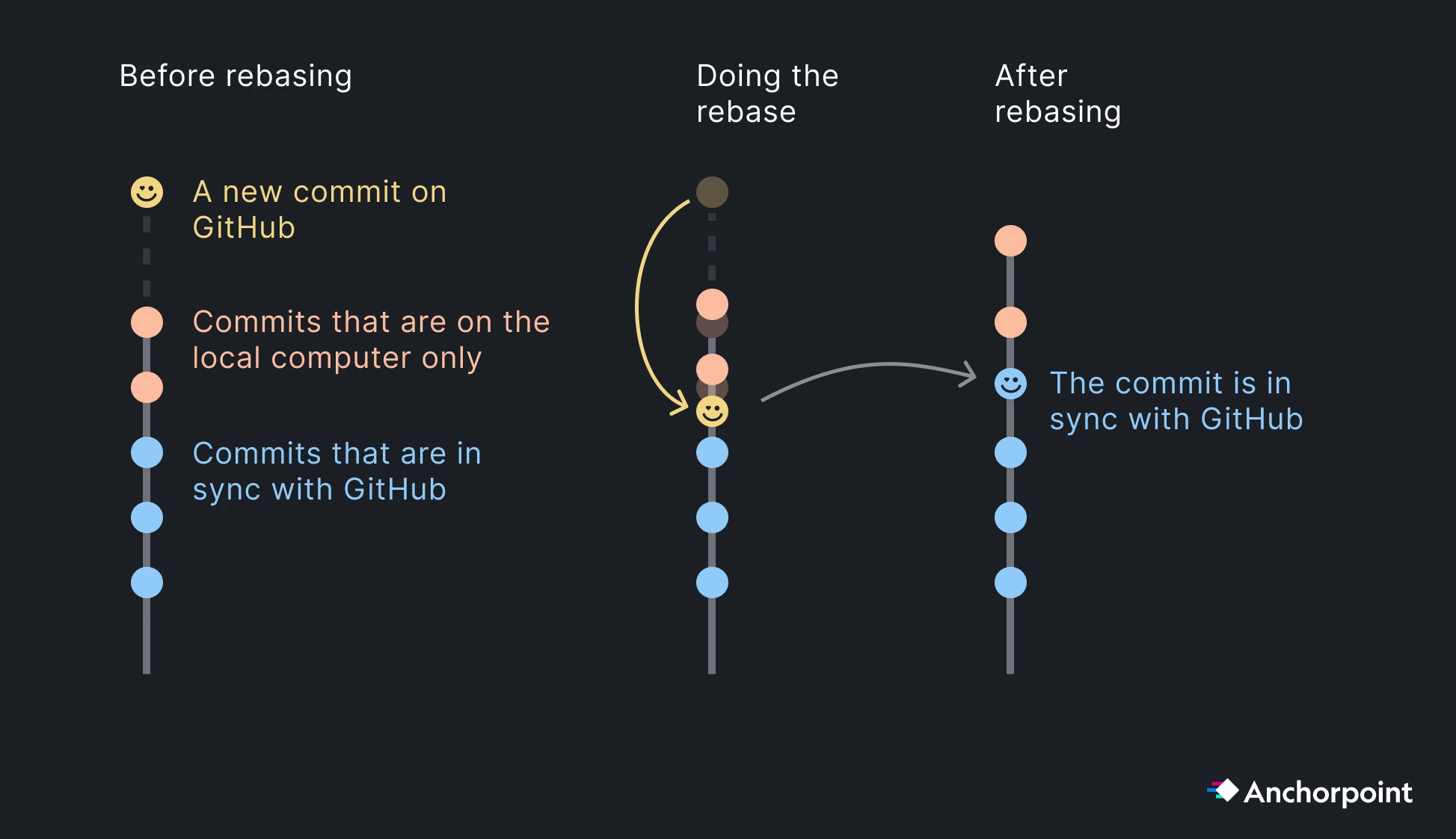
When User A asks GitHub for new changes, he will be able to pull the Commit of User B. Then, Git will not simply add this commit on top of user A, but below the commits of User A. Then, User A can push the local commits and is in sync again with GitHub.
The rebase process happens mostly on pulling new changes and when merging a branch. Anchorpoint will automatically rebase your commits when pulling. If you use the command line you have to explicitly use the git pull --rebase command.
Even when using file locking, it sometimes can happen that merge conflicts appear. When using Git without Anchorpoint, that can be a bit tricky as during the conflict resolving state, Git LFS will replace your actual conflicting file with a 1KB sized pointer. That might feel like data is corrupted, but it is not. After resolving the conflict, the proper file is being restored.
When using Anchorpoint, it will warn you upfront of a pull, if a potential conflict can happen. In this case, Anchorpoint wants you to commit your conflicting file, so that all your work is stored in the version history. Then, you can resolve the conflict.
Resolving a conflict on binary files does not really mean dropping the work of somebody. It’s just about deciding, what is the latest version. You can always restore the “rejected” file version later.
In a studio environment, it is useful to have an automated build creation process so that builds can be quickly handed out to QA or other stakeholders. GitHub Actions allow you to configure such a build pipeline. Jenkins is often used on Unreal projects. For some time, Epic has also developed its own solution called 'Horde' that comes with built-in build graph support.
Git can show you the history of a single file, which can be handy to understand certain modifications and why somebody made things this way. If you are using the command line, you can access the history via git log -p —<filepath>. On text files, it will give you the content, what has been modified. On LFS files such as images, it will only give you the file hash, which is not that helpful.
In Anchorpoint, the history per file is located in the sidebar when you select a file. If you are e.g. inspecting the history of an image, you will also see how the image looked like on a particular version.
If you are using AI as a coding assistant, than you normally don’t need to bother about this. However, when working with multiple AI agents such as Claude Code or Codex in parallel, you don’t want them to work on the same project folder as they will interfere with each other and mess up your codebase. Each agents has to be treated like a human that works in it’s own isolated space.
Git has a build in solution for that, which is called “Worktrees”. A Git worktree is an isolated space that shares. the same .git folder, including all LFS caches. Git will create a new folder on your hard drive where your agent can also work on another branch.
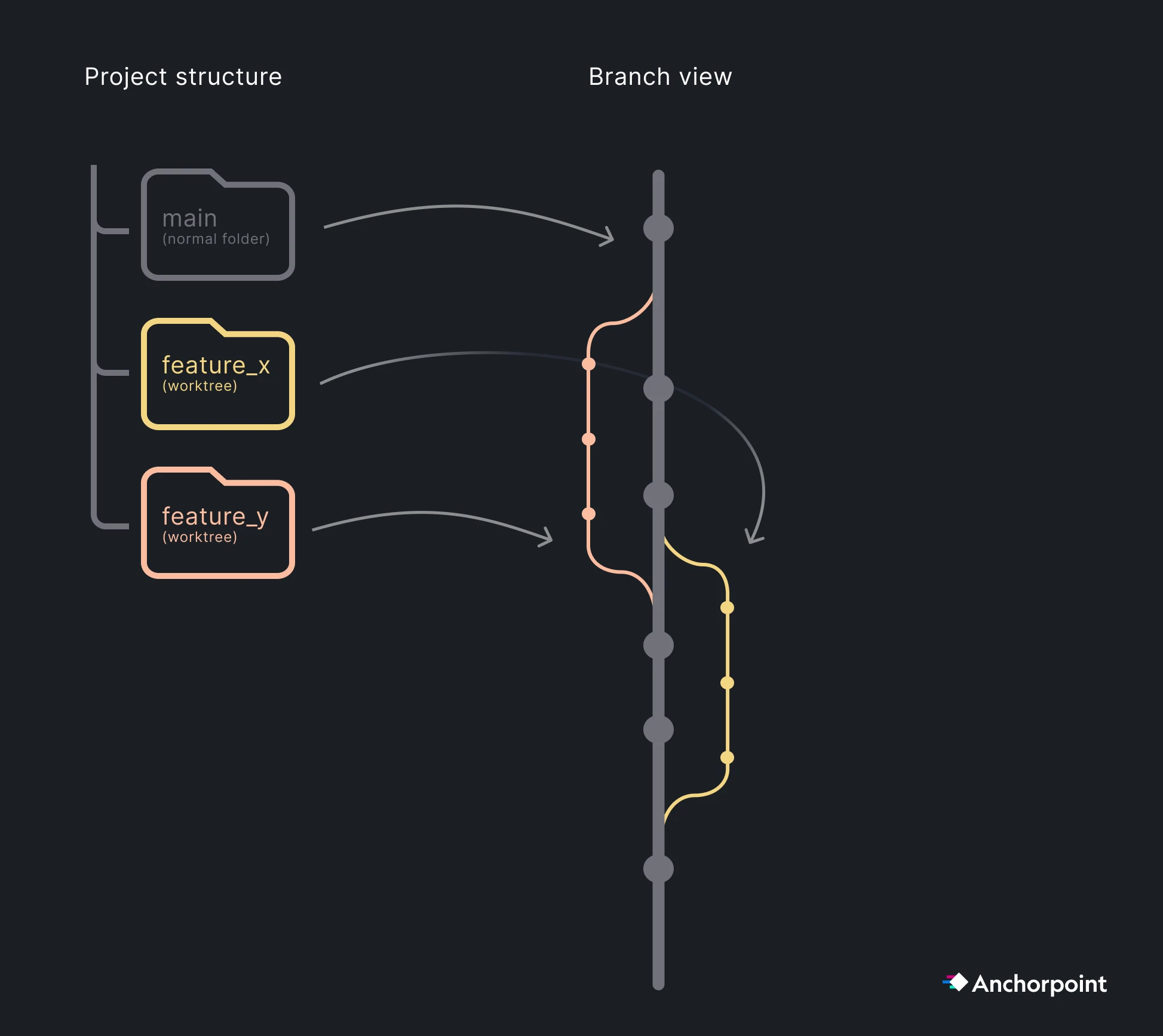
There are some things we need to cover that you only need when working on larger Unreal projects. Large means millions of files and hundreds of people.
To save storage space, you can select which folders of a Git repository should be synchronized and which should not. This is useful if, for example, you store your art assets in the Git repository and the programmer in your team does not want to download these files as he is working on some server implementation.
Another benefit is that selective checkout improves your file tracking performance, especially if you have a repository with millions of files, but you only need to work on a subset of them.
When cloning a repository in Anchorpoint, you can also pick the option that it won’t download any files. Then, in the folder tree view on the left sidebar, you can always pick to checkout a folder. This means, that the folder will be downloaded and tracked by Git.
Using the Git command line, you have to apply a two step process
git sparse-checkout initgit sparse-checkout set path/to/your/folderSubmodules are often a controversial topic in Git. Some developers avoid them due to complexity and indeed, submodules per default have certain caveats.
If used correctly, submodules give you a great tool to manage larger projects. Here are use cases for submodules:
How to import a submodule into your project
Simply use this git command to add a submodule to your project: git submodule add <https://github.com/user/repo.git> path/to/subfolder. If will modify a .gitmodules file that you then need to commit in the same way as the .gitignore, so that everybody in your team will have access to the submodule.
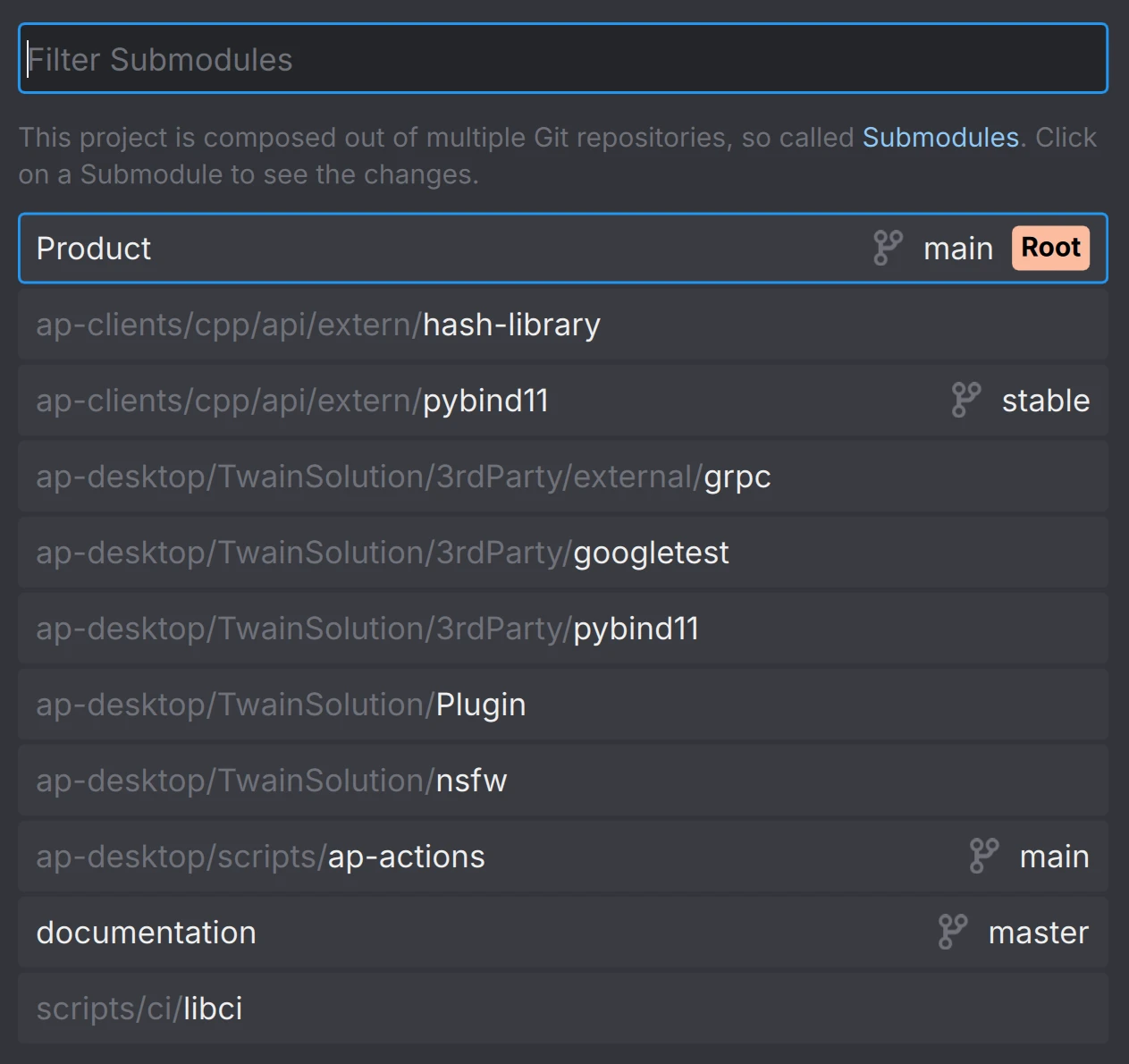
Anchorpoint will show you a list of submodules and manage also the typical caveats of it. You can access the list of submodules from the timeline.
Challenges when working with submodules
The most annoying (but sometimes useful) feature of submodules is the submodule link in the main repository. It makes sure that the submodule version aligns with the one in your main repo. To do that, you will see a submodule link in your main repository, that will always show up as an entry in your changed files if you modified the submodule. In case you are e.g. using an external package, where the correct version is crucial to your game project, that makes a lot of sense. You don’t want to just update the package without doing any adjustments in your main project that might be needed due to breaking changes. You have to treat this submodule link like a file that needs to be committed to you main repository.
However, on many cases, such as working with contractors or importing your asset library, that is simply annoying.
Furthermore, if you use the Git command line or another Git client in a submodule, double check that you work on a commit and not on a detached head. When committing files on a detached head (this means not on a particular previous commit) you are submitting files not on a branch but to nirvana. You have to then use a set of Git commands to get your changes back to the main branch. Anchorpoint protects you from that behavior.
Git normally scans the entire working directory to detect changes — slow on large repos. The filesystem monitor tells Git to let the OS report which files changed instead. It’s very easy to enable it.
Use git config core.fsmonitor true, so your Git configuration will be modified, that it will automatically start the file system monitor on the first Git status.
In Anchorpoint, you can apply this configuration automatically for all your users, so you don’t need to enter this command manually each time for each user.
Working with art (source) assets is much less complicated than working with a game engine. In most cases, you will just work on a separate art asset repository. Unless you are a one man show, do not mix it with the game engine content, for better access controls. In most cases, you will just work on the main branch as there is no need for feature branching.
Art assets can get pretty big, that’s why it’s very useful to use Git sparse checkout, so that you can work only on one particular folder, instead of cloning the art repository.
Like with the game engine, make sure that your .gitignore is configured properly. This example excludes all the blend1, blend2 etc. files that are generated by Blender.
# Blender specific files
*.blend[0-9]*The same applies for Git LFS and your .gitattributes file. Make sure that file types are marked as LFS.
*.png filter=lfs diff=lfs merge=lfs -text
*.fbx filter=lfs diff=lfs merge=lfs -text
*.psd filter=lfs diff=lfs merge=lfs -textIf you use Anchorpoint, it will handle the .gitignore and .gitattributes automatically. When you create a new Git repository, there is an option for “DCCs” when picking the .gitignore template.
This is about GitHub and not Git itself. While GitHub is the most popular platform, it has two issues:
There is a hard limit of 4GB per file. This limit applies to the GitHub Team plan. The Pro and Free plans have a 2GB file limit, and the Enterprise plan has a 5GB file limit. You will not be able to upload files larger than this.
With the free plan and Git LFS activated, you get 10 GB of storage and bandwidth free each month for your repository. If you exceed these limits, you will need to pay $0.0875/GB for bandwidth and $0.07/GB for extra storage. Unreal Engine projects can grow quickly, so you might look for alternatives.
Thanks to the Git ecosystem, we can choose an alternative. Azure DevOps doesn't charge for LFS storage, so we don't have to worry about storage management. However it can sometimes be tricky to set up.
If a high-quality service is important to you, another good alternative is Gitea Cloud or Assembla. Both provide excellent support and security options, and neither suffers from file size limitations.
If you need complete control over your files, a self-hosted Git server is the best solution.
We have a more detailed Git vs. Perforce comparison that includes cost. Here are some hard facts about both systems.
Facts about Git
It's open source and used by 93% of all software development projects. There is a huge ecosystem of tools, cloud providers, and communities. There is no vendor lock-in. You can move your Git projects to another hosting provider if you are not happy with the first one.
Git does most of its work locally, so it's fast. It is fast at creating branches, local commits, and history lookups. Of course, this speed improvement does not count for file transfer, because that depends on your internet connection.
What both can do
Both scale to TB-sized projects with thousands of participants. Perforce is known for this, and with recent developments in Git (with features like Git LFS, sparse checkout, and partial cloning), it works on large projects as well. We have tested it on terabyte-sized repositories, and projects like the Linux kernel that use Git have over 15,000 contributors.
Both have integration with the Unreal Engine, allowing you to submit changes and see the status of files directly from the editor.
Anchorpoint does all this automatically, but if you don't want to use it, you'll need to install Git LFS, which stands for Git Large File storage and is the extension for handling binary data.
To use Git LFS, you need to mark the appropriate file types in the .gitattributes file. This is the configuration file for Git.
The .gitignore file filters file types and folders that should not be uploaded to the git server. In most cases these are cache files created by the Unreal Engine. Here you can download a preconfigured .gitattributes and .gitignore file. Place the .gitattributes file in the root folder of your repository and the .gitignore file in the folder where your Unreal Engine data resides.

