
Teamcenter alternatives in 2026
Discover our top five Teamcenter alternatives, featuring the pros and cons of each and transparent pricing models for hardware and 3D creators.
July 6, 2026
6
min read

When people ask about version control systems for TB sized game projects, then Perforce and Plastic is the answer what we read on internet forums. But based on our experience, Git can definitely do the job as well. With this article we want to showcase, that Git is definitely a version control system that works on large scale game projects.
Disclaimer: We are developing a Git based version control software, named Anchorpoint, but all of the tests we are doing here can be done with the Git command line.
Things that we have seen, about Git and Git LFS, which are not true. They can be true under certain circumstances, but if you configure Git and Git LFS properly, you don’t run into these problems.
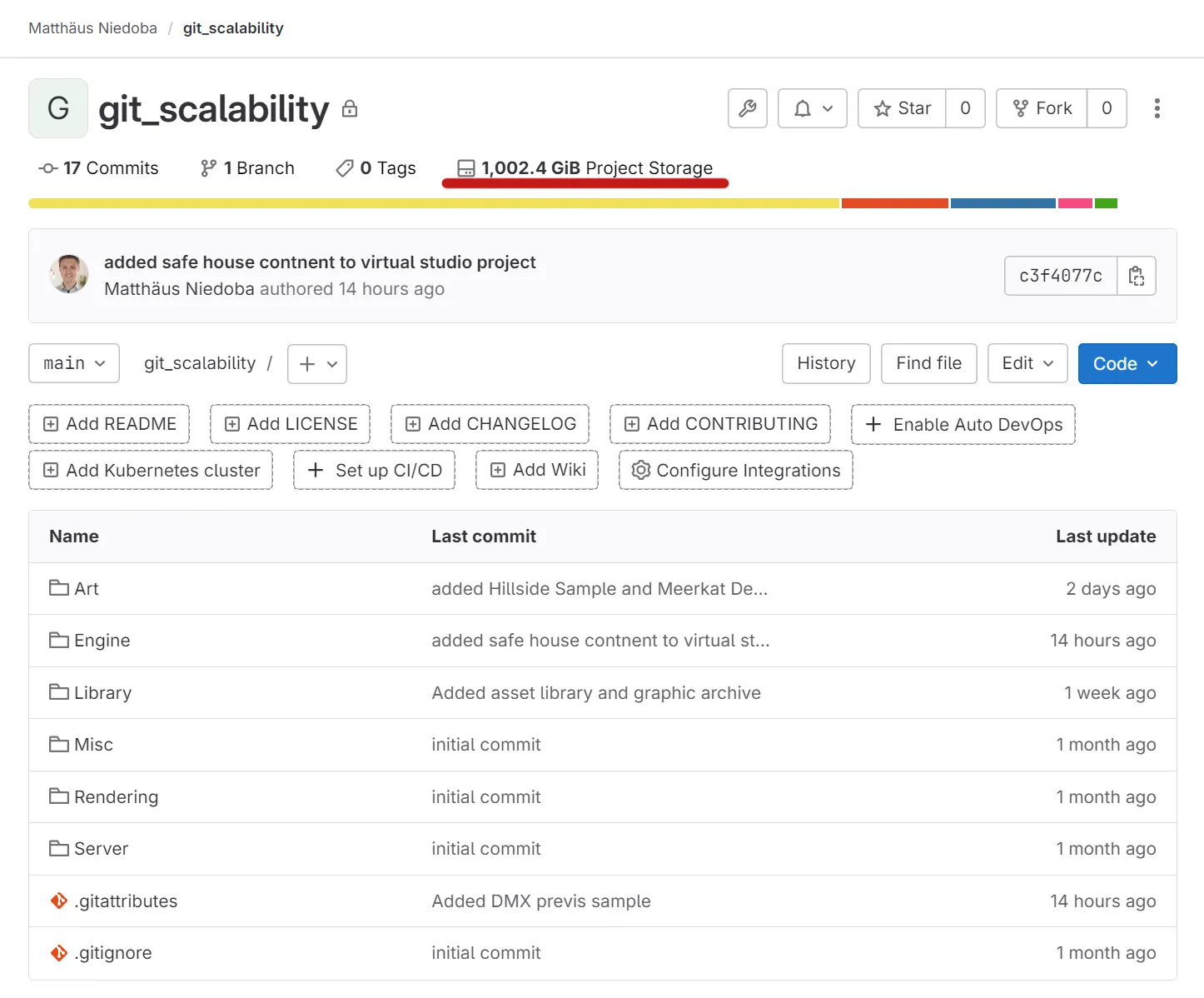
Yes, GitHub (a Git cloud provider) has a file limit of 2GB on the Free and Pro plan, 4 GB on the Team plan and 5GB on the Organization Plan. But this is GitHub only. The great thing of Git is that there are plenty other cloud providers such as Azure DevOps, Bitbucket or many self hosted solutions such as GitLab or Gitea. If you need more than 5GB per file, go for them.
Git itself has no limits on repositories. Cloud providers set limits because their servers run on shared resources. For example, GitHub recommends keeping repositories smaller than 5GB, and GitLab's cloud solution has a limit of 10GB if you are using their free tier only.
However, these limitations don't apply if you're using the Git LFS. Technically, files stored via the Git LFS are stored on an object store that is infinitely scalable.
That’s pretty subjective. Git comes by nature as a command line tool, which is hard to grasp for most people. But right now there are around 36 Git desktop applications that you can choose from to make your life easier.
Git is by far not perfect.
Yes, it’s nature comes from software development projects such as the Linux Kernel. And Git became really popular in the software development world. GitHub alone had 100 million users in 2023. Due to it's open source nature it has the biggest ecosystem of tools, services and communities. This is great, but it also leads to a lot of confusion. The pure Git solution is the command line. GitHub is not the same as Git. Git LFS is an add-on, etc. Take Dropbox, on the other hand. There is a company that provides tools, cloud storage, and support for a single system.
You cannot provide access on a particular file or folder like on a Dropbox or on systems such as Perforce. In Git, you checkout the whole repository and have access to all the files. That’s because it’s design as a decentralized version control system. The only way to limit access is to split up your work among multiple repositories, which is not that convenient than just giving permission on a folder level.
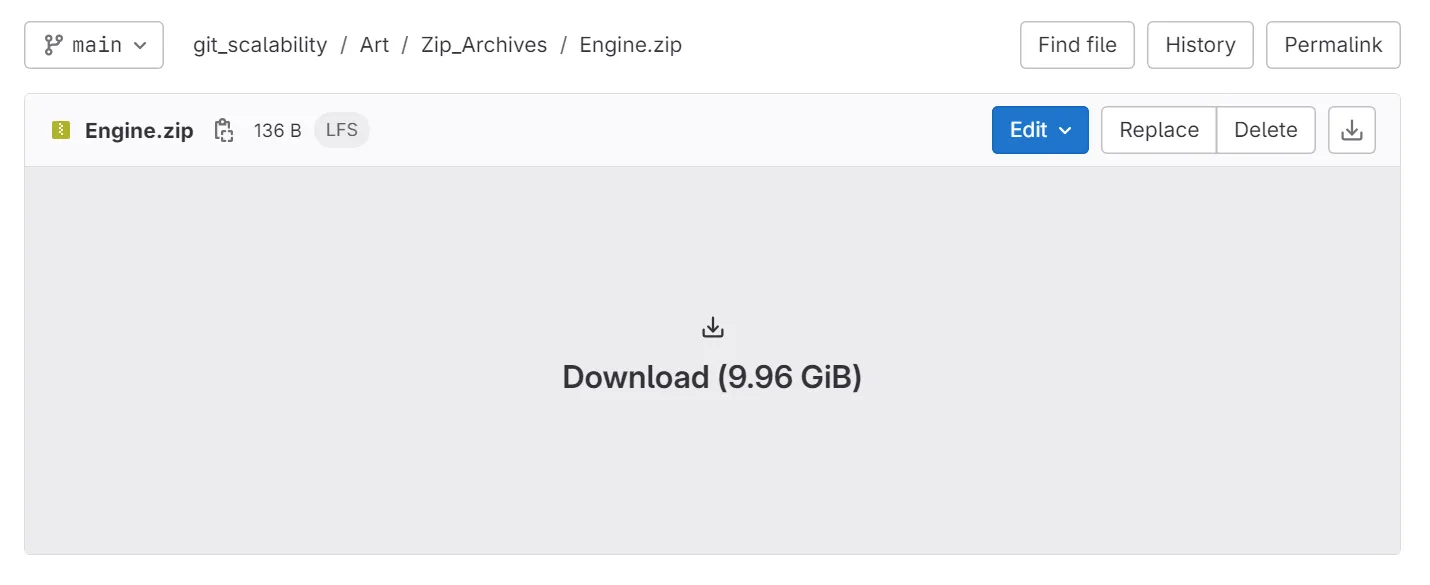
We conducted a test where we committed a project with 385.493 files in total with a total size of 1 TB to GitLab using Anchorpoint. Again, you can also use the Git command line for that. Tests were conducted on a 2022 Dell XPS laptop with 32 GB of RAM and an NVMe SSD.
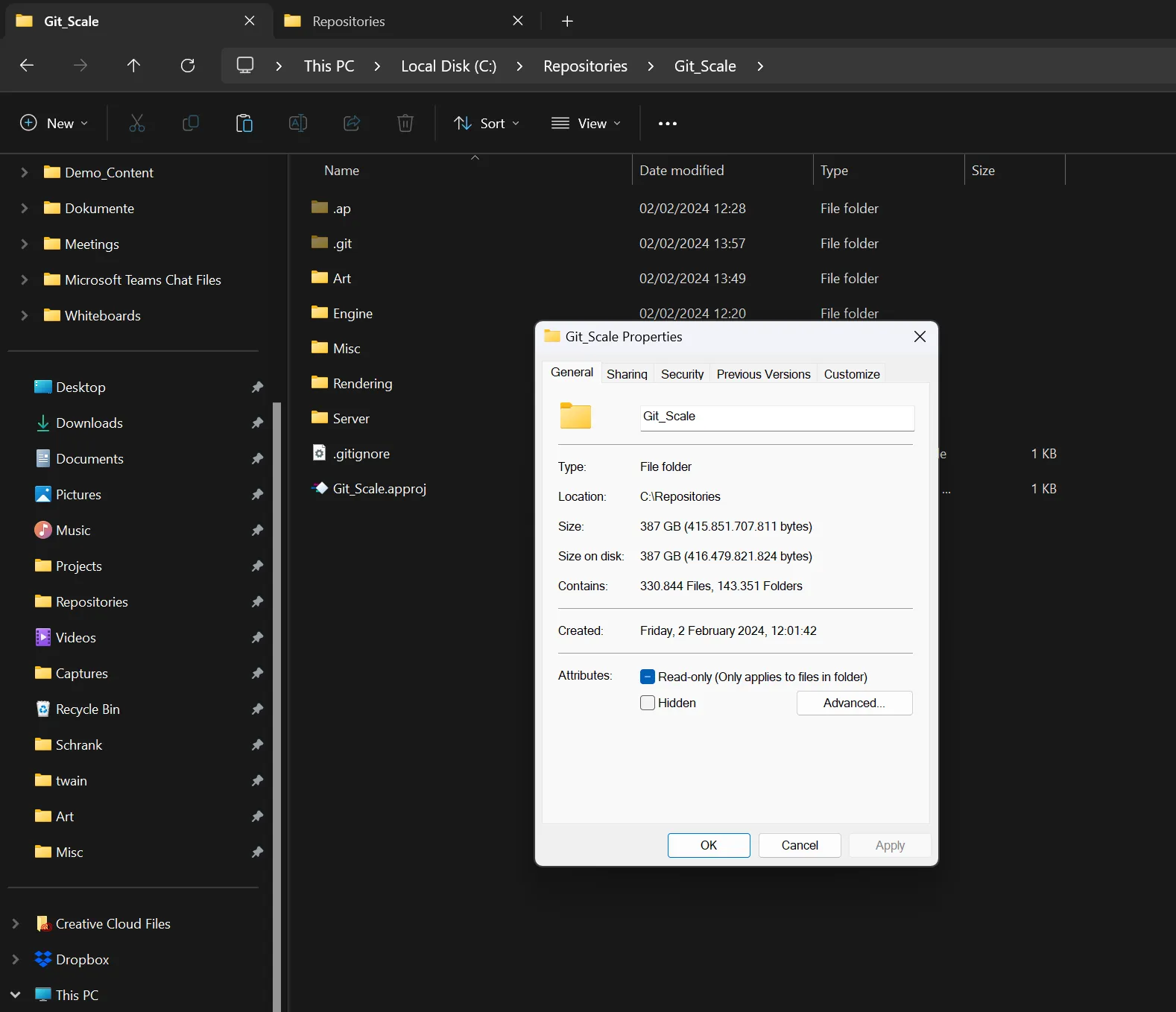
The first commit included 281.876 files (330.844 project files minus the ones that are ignored by a .gitignore) with a total size of 387 GB. To make this happen, we needed at least 400 GB of free space on our hard drive because a commit copies all files to a temporary location. After creating the commit, we pushed the files to GitLab. Once the push was finished, the temporary location was cleaned by Anchorpoint.
The commit in Anchorpoint took 2 hours and 43 minutes
This includes configuring all LFS and add all the necessary file extensions (14 minutes and 30 seconds) as well as staging the files and creating the commit. In the command line you would need to track the LFS files manually.
The push to GitLab took 30 hours on a 30 MBit upload speed with some network timeouts.
In a normal production environment, you don't need to have all the art assets and rendering of the whole project on your computer.
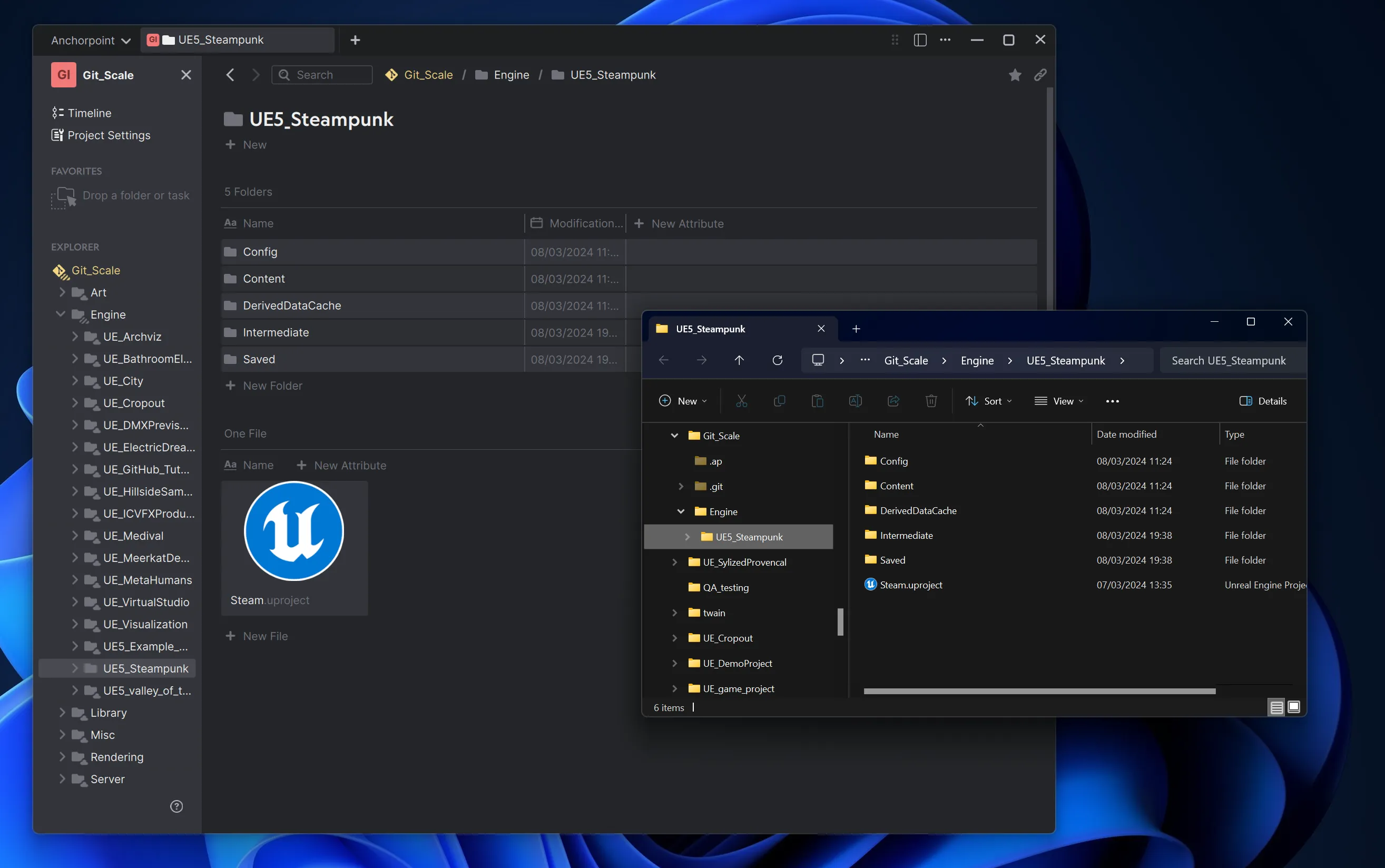
Using selective checkout (Git sparse checkout) in Anchorpoint, we removed all the files and folders locally, while keeping the content on GitLab. With this, Git only needs to check a fraction of our project files, saving you space on disk.
The only thing that we left was an Unreal Project based on the Wild West City asset pack with a size of only 3.67 GB.
The test repo has 1TB (1.004 GiB) and a total file count (excluding files, that are ignored by the .gitignore) of 385.493. To make a performance test, we changed 10 files in Unreal Engine.
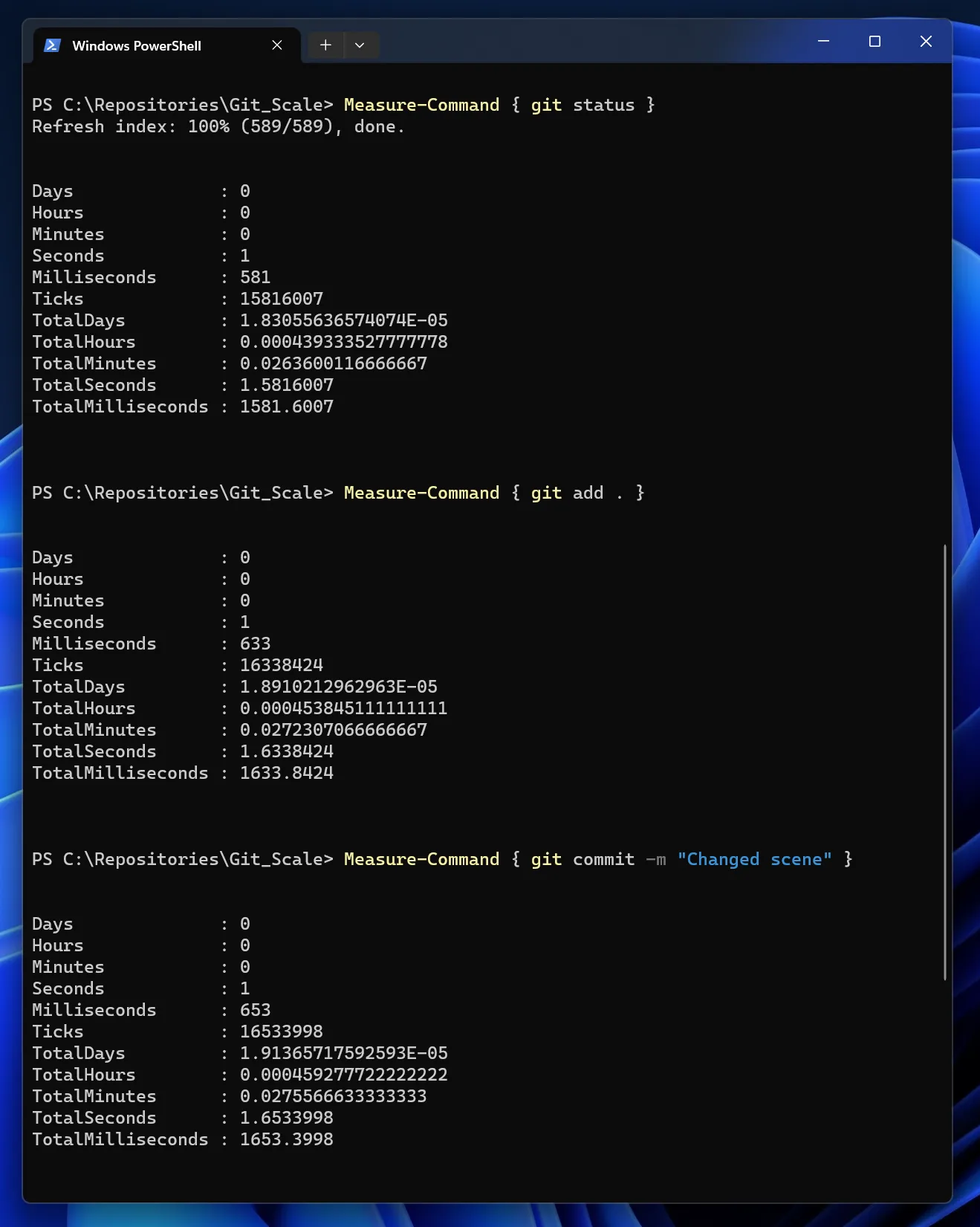
Let’s start with large projects in terms of people. Think of the Linux Kernel with over a million of commits from almost 15 thousand contributors. We don’t think we need to prove that Git works on large projects when it comes to people. Bigger projects require to learn processes. So teaching a team using branches and doing Pull Requests might be not a bad idea.
Git LFS is an add-on for Git that manages large files, making it extremely useful in game development. It's part of the Git ecosystem and is supported by most cloud services and desktop applications for Git.
git lfs install
git lfs track myFile.fbx
If you are using the command line, you only need to run git lfs install once. You don't need to do this for every repository. The command git lfs track needs to be run for every file type in your repository to mark these files as LFS files. Alternatively, you can manually modify your .gitattributes file.
Normally, Git downloads every single file in a project, which isn't great if you only need certain parts, like just the code and not the art assets. Sparse checkout lets you pick just the folders you want, saving time and space.
git sparse-checkout init --cone
git sparse-checkout set myFolder
First, you need to perform an initialization. Then, you can select the directories you want to check out (download).
Partial clone is another Git feature that functions like a more integrated version of Git LFS within the Git core. It allows you to download only the essential parts of a project, such as the history but not the large binary files, until you need them. Most cloud providers support this feature. However, files stored in the Git repository can encounter size limits for repositories at the moment. This issue does not apply to Git LFS.
git clone --filter=blob:none --no-checkout myRepositoryURL.git
git checkout myBranchName
Including the -filter=blob:none means that no binary files will be downloaded. This can be addressed in a later step using checkout.
Shallow clone is useful for projects with extensive histories. It allows you to download only a portion of that history, such as the changes from the last year, rather than the entire history from the beginning. This approach can significantly speed up the process of an initial clone of the repository.
git clone --depth=1 myRepositoryURL.git
Instead of cloning the entire history, Git will only retrieve a fraction of it, making the clone process much faster.
When it comes to selecting a Git server for scalable game projects, a self-hosted GitLab on AWS (or any Infrastructure as a Service, IaaS, provider) is a good recommendation. GitLab stands out for its scalability. With a self-hosted setup, you have full control over the server's speed, as you're not sharing resources like memory or processing power with others. This setup also allows you to choose the server's location, which can be crucial for performance and compliance reasons.
Additionally, GitLab provides a comprehensive platform for various development operations, including issue tracking and Continuous Integration/Continuous Deployment (CI/CD) pipelines.
Configuring LFS
It's essential to set up Git LFS properly to push files to an S3 object storage, which offers infinitely scalable storage for large files. This setup ensures that we won't encounter any storage limitations that would arise from storing all LFS files on the drive of the virtual machine.
Configuring the logging system
You don’t want that your logging system will flood the hard drive and take the necessary space for our Git repository. Plain text files will be stored in the repository on the virtual drive and not the S3 object storage using LFS.
To manage log files in a self-hosted GitLab on AWS and prevent them from filling up the disk, it's essential to configure log rotation effectively. GitLab uses logrotate, a system utility that manages the automatic rotation and compression of log files. By default, GitLab's log rotation settings might not be optimized for your specific needs.
All of the aforementioned Git features are accessible via the command line, which is free to use. As of today (March 2024) graphical Git clients don’t support sparse checkout and not all of them can handle a huge amount of files in a commit.
Anchorpoint (our Git application) was made to handle that and it simplifies the setup of Git Large File Storage (LFS) by handling configurations automatically. So if an artists adds a new file type (e.g. an EXR file) to the repository, that is not a problem, because Anchorpoint takes care of that.
Furthermore Anchorpoint comes with a GitLab integration, automatic LFS cache cleanup, file locking and sparse checkout. It is a paid solution. Whatever you use, is up to you.
With the latest developments in Git, it has transformed itself into a scalable solution for game development. Besides the lack of fine-grained permission control, Git is a good choice, especially due to its open-source nature and the huge ecosystem of tools and services.
No, Git LFS does not have limitations on file size. It was designed to handle large files, making it an good solution for managing big binary files such as those used in game development. Git LFS stores these large files separately from your repository, allowing you to work efficiently without hitting repository size limits.
Git sparse checkout is a feature that lets you selectively download only the directories or files you need from a repository, rather than cloning the entire project. This is especially useful in large projects where you might not need access to all the files, such as when working with only certain parts of a game's assets. It helps save time and disk space by allowing you to focus on the files that are relevant to your current task.
Branching in Git is a way to diverge from the main line of development and continue to work independently without affecting the main project. It's like creating a separate copy of the project where you can develop features, fix bugs, or experiment with new ideas. Once you're done, you can merge your branch back into the main project. Branching is essential for organizing work among multiple team members, allowing for parallel development without conflicts.

